Lecture 15
Analysis of Policy Interventions
2026-01-08
Welcome!
This week:
Analysis of Policy Interventions in Computational Urban Science

Policy evaluation
Example: using before-after comparisons to evaluate the impact of transportation policies:

Example: effects of congestion pricing in NYC
NYC launched a congestion pricing program aimed at reducing traffic congestion in Manhattan below 60th St.

Example: effects of congestion pricing in NYC
First initial data: https://www.congestion-pricing-tracker.com (from a student in Northeastern!). Using Google Maps, commuting times for different routes in and out of Manhattan.

Example: effects of congestion pricing in NYC
They found a small effect on the average commuting time on routes affected by the policy

Example: effects of congestion pricing in NYC
The main effect is on the commuting times at different times of the day

Example: effects of congestion pricing in NYC
Results from other data companies (INRIX, MTA) show a small impact on the average speed (around 20%) within the Central Business District (CBD), Manhattan. This might signal that the impact was mostly on private vehicles, not Ubers + delivery.

Example: effects of congestion pricing in NYC
Most of these evaluations:
Use simple counterfactuals:
- Do the before-after comparison of the same routes. Typically, they compare the same week in 2025 with 2024.
- Take as counterfactual travel times in other cities, like Boston/Chicago.
Do not control for potential spill-overs
Do not implement a systematic causal inference framework

Example: effects of congestion pricing in NYC
In a recent paper, [1], Cook et al. took a more causal analysis of congestion pricing. They
- Use Google maps traffic trends in NYC and other cities.
- They measure the average speeds of travel within and to the CBD
- They found that the average speed on CBD road segments increased from 8.2 mph to 9.7 mph before-after the intervention

Average daily speed in the CBD (red) compared with a handful of other cities
Example: effects of congestion pricing in NYC
Even though only NYC implemented congestion pricing, average speeds in most cities increased in January and February. To get a better counterfactual, they used a synthetic control formed from other cities. They found a significant ATT (15%) on daily and hourly average speed.
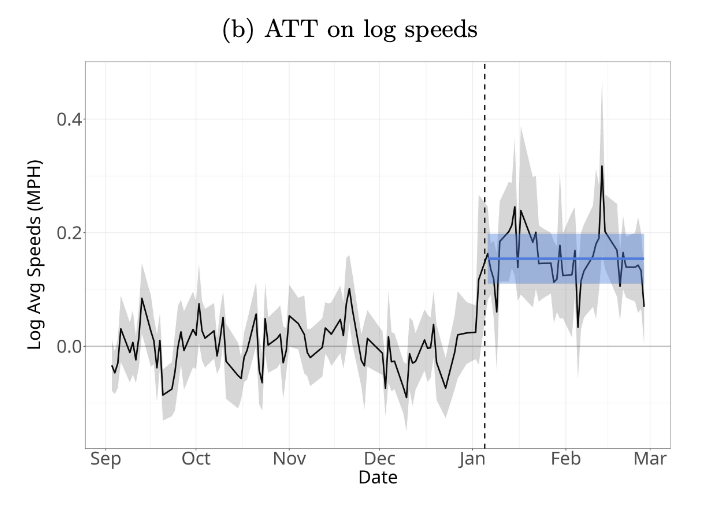
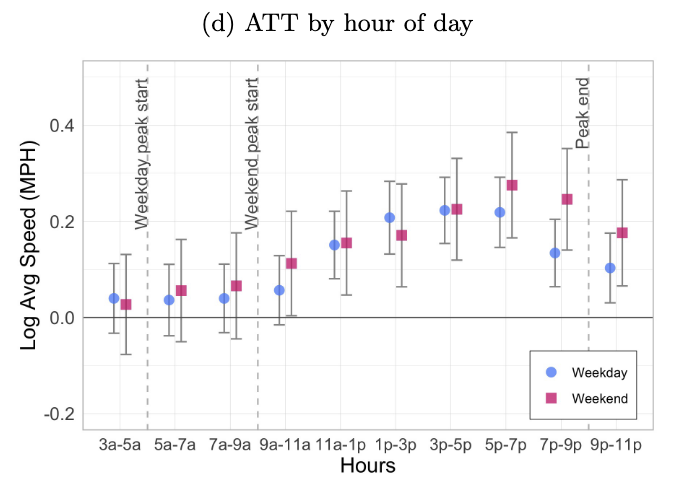
Example: effects of congestion pricing in NYC
The effect is mainly within and to CBD, although small increases in speed of 4% can be seen on trips to other areas that go through the CBD.

Example: effects of congestion pricing in NYC
Using CATE, they also investigate the effect across different groups. They found similar effects across the income distributions.

Example: measuring the impact of slow zones on street life using social media
In the early 2000s, Paris began to promote sustainable transport models. The Paris Pedestrian Initiative implemented a street-sharing program to promote alternative modes of transportation (bikers, pedestrians). A key component of this program was the Zone 30 initiative to create slow zones.

Example: measuring the impact of slow zones on street life using social media
To do that they fixed the speed limit of 30km/h, created more space for bikes, sidewalks, and parking space was converted to terraces in some streets.

Example: measuring the impact of slow zones on street life using social media
There were 141 slow zones introduce in Paris, located within the central area of Paris and implemented across ten years.

Example: measuring the impact of slow zones on street life using social media
One of the key components of this policy is its implementation: it was done at the level of the district, which means that streets outside of those slow zones were not affected by the policy. This was used by Salazar-Miranda et al. [2] to evaluate the impact of policy using causal methods.
They define treated streets as those within slow zones and control as those 100m or less from the boundary of slow zones.
Example: measuring the impact of slow zones on street life using social media
Their choice of treated and control groups was made to maximize their similarity across all other potential confounders like length, proximity to the city center, transit stops, parks, etc., that might affect the outcome of the policy. They only found differences in segment length, thus they control for it later.

Example: measuring the impact of slow zones on street life using social media
First: does human activity vary across the boundaries of slow zones? There appears to be a discontinuity in the regressions of activities across the boundaries. This justifies their choice of control and treatment groups.

Example: measuring the impact of slow zones on street life using social media
They claim that, since control and treated segments of the same street at different sides of the boundary are significantly different in terms of characteristics (apart from the street length), then \(\beta\) can be interpreted as the causal impact. Here are the results for different outcomes (44% increase in the number of tweets!)

Example: measuring the impact of slow zones on street life using social media
However, they found that the effect is only significant for early cohorts (2010) of slow zones. Probably because of under-powered statistical analysis

Example: effects of EV charging stations on business
Electric Vehicles (EVs) offer a possibility to alleviate the problem of pollution in our cities. Some policies, like the Infrastructure Investment and Jobs Act (IIJA) in 2021 ($7.5B) promote the creation of public EV charger stations (EVCS) across the nation.
However, the importance of public EVCSs extends beyond their primary function: they can influence the economic outcomes of surrounding businesses. Does the foot traffic around EVCS boost or harm those businesses?

Example: effects of EV charging stations on business
Their data includes when a charging station is opened. They considered that all POI locations within a 500m during the study period are part of the treatment group. Control are POI locations outside that 500m boundary.

Example: effects of EV charging stations on business
Once this is done, typically, we should observe that the distribution of covariates between treated and control groups should be similar

Example: effects of EV charging stations on business
They found that adding a new charging port resulted in a 0.21% increase in customer count and a 0.25% in spending in 2019 and 0.14% and 0.16% in 2021-2023.

Example: effects of EV charging stations on business
The effect is very small (!!) and has some demographic, temporal, and spatial heterogeneity. For example, they found that for underprivileged regions, the effect was 0.17%/0.29% in 2019 and that the effect diminishes with distance to EVCS and does not increase with time.

Example: effects of EV charging stations on business
They also found some differences across categories. Only Restaurants and Grocery/clothing stores seem to be affect (and only for fast chargers)

References
![]()