library(tidyverse)
library(arrow)
options(arrow.unsafe_metadata = TRUE)
library(DT) # for interactive tables
library(knitr) # for tables
library(ggthemes) # for ggplot themes
library(sf) # for spatial data
library(spdep) # for spatial econometrics
library(caret) # for machine learning
library(stargazer) # for regression tables
sf_use_s2(FALSE) # switch off geometry. Speed up calculations
theme_set(theme_hc() + theme(axis.title.y = element_text(angle = 90))) Lab 13-1 - Environmental inequalities
Objective
In this lab, we will study environmental inequalities in the Boston Metropolitan Statistical Area (MSA). We are going to
Investigate exposure to pollution in different demographic groups using the PM2.5 data from the Atmospheric Composition Analysis Group at WashU, tree coverage from the US States Department of Agriculture’s Forest Service, and census data.
Study the unequal Urban Heat Island effect in Boston using data from the NIHHIS institute.
Setting up the environment
Loading the data
Research has found a significant inequity in the exposure to pollution in our cities [1] [2]. Some groups (low-income, minority groups) are more exposed to pollution than affluent communities.
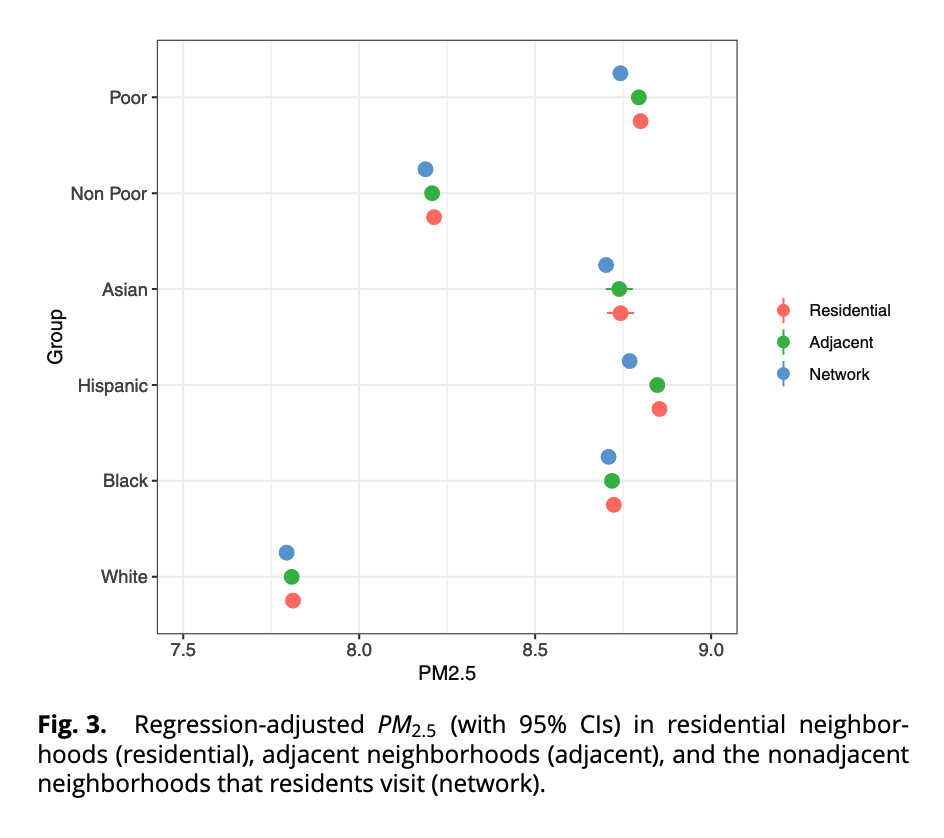 Let’s reproduce those results in the Boston MSA. As in Lab 1-1 we can use the PM\(_{2.5}\) levels that the Atmospheric Composition Analysis Group at WashU publishes (see [3]). This time we are going to use the annual averages in 2022:
Let’s reproduce those results in the Boston MSA. As in Lab 1-1 we can use the PM\(_{2.5}\) levels that the Atmospheric Composition Analysis Group at WashU publishes (see [3]). This time we are going to use the annual averages in 2022:
require(terra)
pm25 <- rast("/data/CUS/labs/6/V5NA04.02.HybridPM25.NorthAmerica.2022001-2022364.nc")Let’s have a look to it:
require(tidyverse)
require(tidyterra)
ggplot() +
geom_spatraster(data=pm25) +
scale_fill_whitebox_c(
palette = "muted",
breaks = c(0,0.01,0.1,1,10,100),
guide = guide_legend(reverse = TRUE)
) +
labs(fill="PM25") 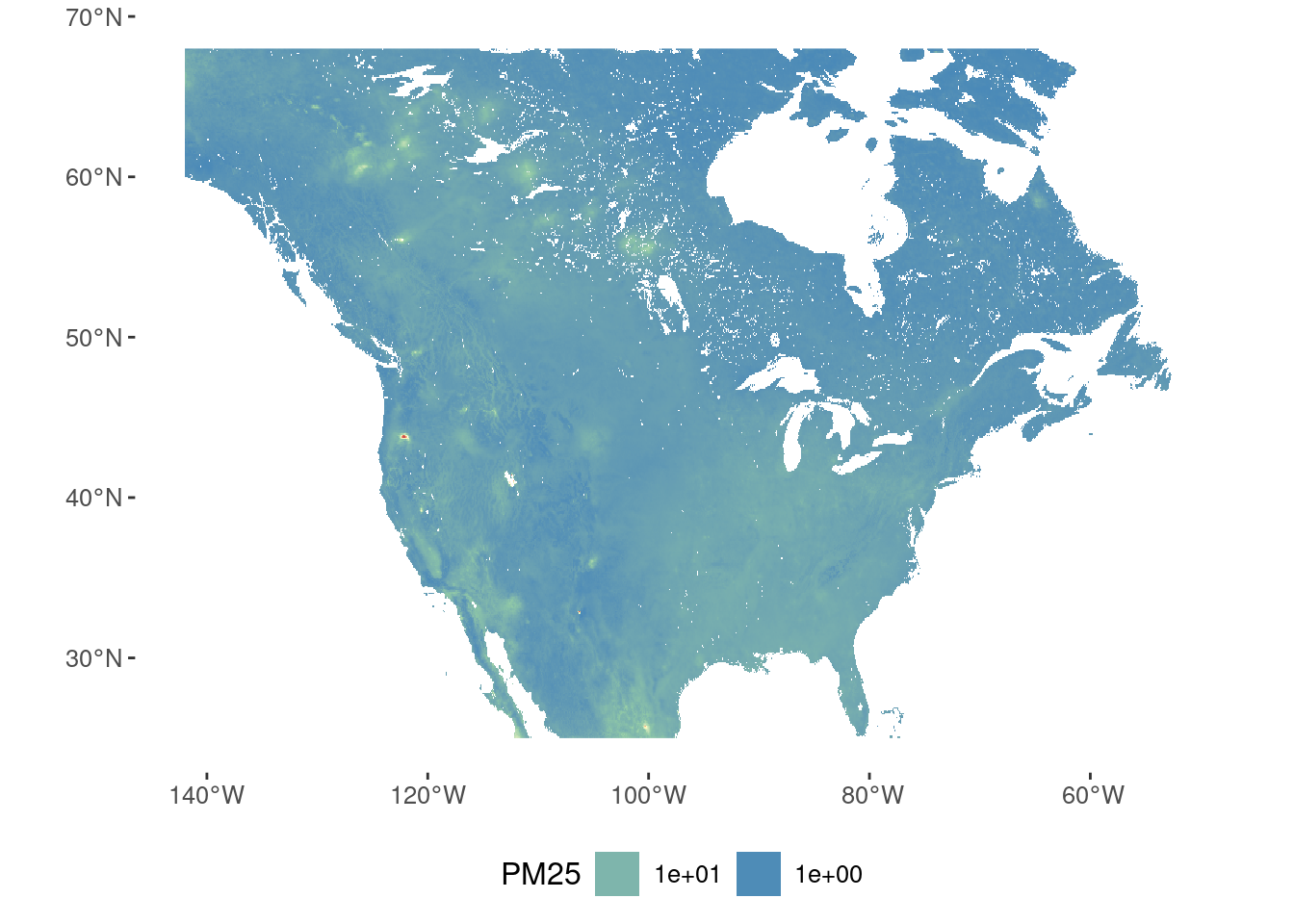
Modeling who is exposed to pollution
To model exposure to pollution (PM2.5), we are going to consider two different groups of variables
The first group is composed of demographic variables to study what groups are more exposed to pollution.
The second group is variables that could mediate the effect, like the extent of greenery in those areas.
Demographics
We use the American Community Survey 2021 data to get the demographics of the Boston MSA by CBG.
census <- st_read("/data/CUS/labs/6/14460_acs_2021_boston.geojson") |>
st_transform(4326)Reading layer `14460_acs_2021_boston' from data source
`/data/CUS/labs/6/14460_acs_2021_boston.geojson' using driver `GeoJSON'
Simple feature collection with 3418 features and 66 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -71.89877 ymin: 41.56585 xmax: -70.32252 ymax: 43.57279
Geodetic CRS: NAD83We are going to consider the following variables:
census_model <- census |>
mutate(median_income = log(median_income),
prop_bachelor = education.bachelor/total.education,
prop_black = race.black / race.total,
prop_employed = employment.civilian_employed / employment.civilian_labor_force,
prop_car = trans.car/trans.total) |>
select(GEOID, median_income, prop_bachelor, prop_black, prop_employed, prop_car) |>
drop_na()Canopy
The US States Department of Agriculture’s Forest Service maintains a tree canopy covers datasets for the US
canopy <- read_csv("/data/CUS/labs/13/tree_coverage_Boston.csv",
col_types = cols(GEOID = col_character(), tree_coverage = col_double()))This dataset contains the proportion of canopy in each CBG. Let’s merge it with the census data:
census_model <- left_join(census_model, canopy, by="GEOID")Here is it:
require(leaflet)
pal <- colorNumeric("YlGn", domain = census_model$tree_coverage)
leaflet(census_model) %>%
addProviderTiles("CartoDB.Positron") %>%
addPolygons(stroke = FALSE, smoothFactor = 0.2,
fillOpacity = 0.8, color = ~pal(tree_coverage)) |>
addLegend(pal = pal, values = ~tree_coverage,
opacity = 0.7, title = "tree_coverage %")